For improved animal health and performance, and more sustainable farming.

Problem description
The global demand for animal products is expected to increase by 70% by 2050. This rapid increase in demand for animal products poses significant challenges for the animal agriculture industry, including the need to increase efficiency and sustainability while improving animal welfare and health. Machine learning is here to help.
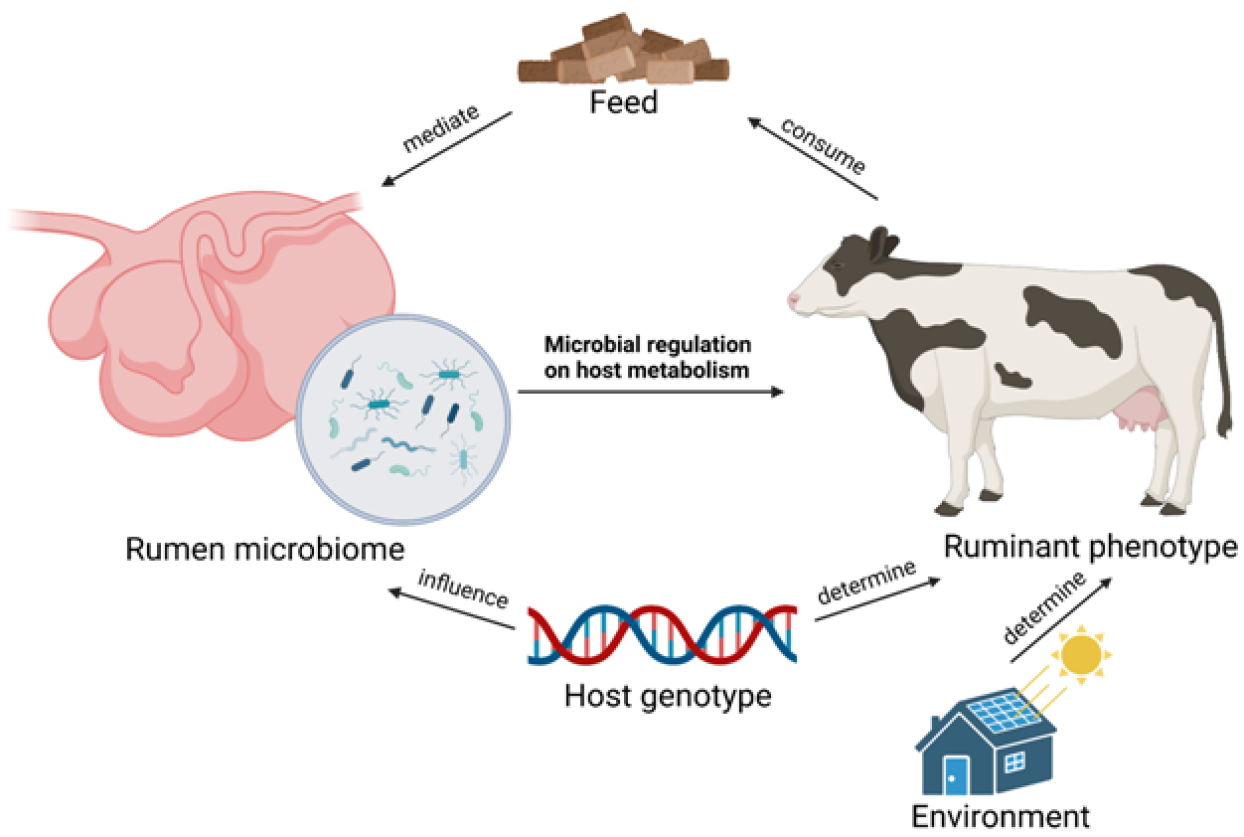
The gut microbiomes of farm animals, the diverse microbial communities that inhabit the animals’ gastrointestinal tracks, play crucial roles in their health and performance. Manipulating the animal microbiome by nutrients such as feed additives, prebiotics, and probiotics is a promising approach for improving sustainability and efficiency in animal agriculture. That said, the highly complex relationship between the animal microbiome, feed, and health and performance poses challenges in data analysis to derive actionable insights.
References
-
Unveiling microbial biomarkers of ruminant methane emission through machine learning, 2023
-
Host genetics and the rumen microbiome jointly associate with methane emissions in dairy cows
-
A heritable subset of the core rumen microbiome dictates dairy cow productivity and emissions
-
Identification of shared and disease-specific host gene–microbiome associations across human diseases using multi-omic integration [Webinar]
Goal
The goal of this PhD project is to develop machine learning approaches that are tailored to analyse complex datasets of animal microbiome, feed, and health and performance to identify patterns and relationships that are not apparent through traditional statistical methods. This information can then be used to develop precision feed products that are optimized for animals of different ages, breeds, locations, etc., resulting in more efficient and effective feeding practices that improve animal health and performance.
Project team



Project details